Out on the GenAI Wild West: Part I - Red Team Redemption

Out on the GenAI Wild West
Enterprise AI adoption is outpacing security at breakneck speed. Organizations are rapidly deploying large language models (LLMs) across customer service, code generation, and business intelligence—driven by competitive pressures that often prioritize speed-to-market over security posture.
While some AI security challenges mirror traditional software security—such as supply chain/data provenance, input/output filtering, and access controls—LLMs introduce new attack and defense patterns. Unlike conventional software systems, which exhibit predictable behaviors, LLMs are probabilistic systems that generate unpredictable responses and exhibit emergent behaviors that are difficult to anticipate. The business impact of these risks can be substantial: Google’s market value slid $100bn after Bard shared inaccurate information in a promotional video, illustrating how AI failures translate directly to financial and reputational consequences.
Traditional security tooling, frameworks, and red teaming approaches, designed for deterministic software, struggle to aptly secure AI systems where attacks exploit the capabilities that make LLMs valuable—natural language understanding, reasoning, and content generation. Attackers can manipulate conversational context, inject malicious prompts through seemingly innocuous natural language requests, and exploit training biases to extract sensitive information or bypass safeguards.
This reality has driven the security industry to adapt traditional red teaming practices for the AI era. Red teaming large language models (LLMs) is a systematic process of probing your GenAI application (or model by itself) with adversarial inputs to uncover vulnerabilities before attackers do (ok, yeah - we know what red teaming is… right?).
Well, something fundamentally new has emerged: AI itself is now used to red team AI—not just automating test execution, but inventing, mutating, and scaling new exploits in ways that traditional penetration testing tools cannot. Unlike legacy security scanners, which rely strictly on static signatures or rule-based fuzzing, LLM-powered red teamers can generate novel attack strategies, adapt to defenses in real time, and discover failure modes that would be impractical or impossible for humans to find manually.
Red Team Redemption
Early LLM red teaming was typically manual—security experts crafting prompts to elicit unsafe or unintended outputs. This approach, while creative, was slow and limited in scope and scale. Recent research shows that AI-driven red teaming is not just faster—it’s also exhaustive and can demonstrate a high degree of novelty, enabling exploration of attack spaces in ways humans struggle to match. Automated agents can run thousands of iterations, mutate prompts with subtle syntax changes, and systematically probe for weaknesses that would be tedious or impossible for manual testers to uncover.
- HARM (Holistic Automated Red Teaming) uses multi-turn LLMs to generate and refine attack prompts, leveraging risk taxonomies to expose vulnerabilities systematically. HARM demonstrated that automated agents can uncover more issues faster than human testers alone.
- AutoRedTeamer introduced a dual-LLM architecture where one model generates attacks and another learns from new vulnerabilities, enabling continuous adaptation. This approach achieved 20% higher attack success rates on HarmBench against Llama-3.1-70B while reducing computational costs by 46% compared to existing automated approaches.
- GOAT (Generative Offensive Agent Tester) framework achieved 97% attack success against Llama 3.1 and 88% against GPT-4 on standard benchmarks.
- MasterKey Jailbreaker demonstrated that even closed-source, heavily-guarded LLMs remain vulnerable to systematic, AI-generated attacks, with success rates over 20% across top chatbots.
- ADV-LLM fine-tuned adversarial LLMs for attack generation, transferring exploits to proprietary models with up to 99% success on GPT-3.5 and nearly 50% on GPT-4.
- TAP (Tree of Attacks with Pruning) showed that iterative, feedback-driven prompt mutation can reliably bypass safety guardrails, with more capable models often being easier to break.
Using AI to red team AI is not just a step up in efficiency—it’s a fundamental shift in capability and, frankly, an operational necessity. The same AI capabilities defenders use to uncover vulnerabilities are equally available to adversaries. Automated, adaptive AI agents can invent, mutate, and scale attacks in ways that legacy penetration testing exercises never could, exposing both known and unknown risks. This arms race drives rapid innovation in offence and defense for LLM security.
For regulated industries, this represents existential risk: compliance violations, regulatory fines, and reputational damage from a single successful exploit. The risk of data leakage or unauthorized behaviors from non-deterministic GenAI applications must be measured and mitigated with evidence-based rigour.
The question isn’t whether adversaries will target your GenAI deployments—it’s whether your security program can evolve as fast as they do.
There’s a snake in my boot!
CISOs face a fundamental challenge: how do you quantify risk when model providers control both the product and the evaluation metrics? Most security assessments rely on vendor-supplied benchmarks, internal testing methodologies, or static datasets that suffer from “dataset rot”—where models have already learned to defend against known attack patterns (e.g., from adversarial datasets of known exploits like prompt injections) through their training process.
This creates a critical blind spot. LLMs are inherently non-deterministic systems where identical inputs can produce different outputs based on temperature settings, model architecture, and computational paths on inference. This probabilistic behavior means security assessments must account for statistical variance: a prompt that fails 90% of the time may still succeed enough to represent significant risk. Additionally, models can exhibit “alignment drift”—where safety behaviors degrade under conversational pressure or as context windows expand, making single-turn evaluations insufficient for real-world risk assessment.
The mathematical basis for this context degradation lies in how LLMs process information. Neural networks operate as statistical analysers that predict next-token probabilities using learned patterns from high-dimensional embedding spaces—not as search engines with perfect recall. Text segments are converted to numerical embeddings (vectors in high-dimensional space), where semantically similar concepts cluster together based on training data patterns. As context length approaches the model’s maximum token limit, architectural constraints can induce performance degradation: the model must balance attention across increasingly long sequences while maintaining coherence with both early context and recent conversational turns. This leads to what is known as contextual degradation—where the model’s ability to maintain consistent reference to earlier parts of long conversations diminishes due to fixed attention window limitations. For adversaries, this represents an exploitable vulnerability where malicious instructions positioned strategically within extended conversations may receive reduced attention from safety mechanisms that were primarily trained and tested on shorter, more focused contexts.
The opacity problem compounds when organizations deploy multiple models across different use cases. Without independent, standardized evaluation frameworks, it becomes impossible to compare security postures, validate vendor claims, or make evidence-based architecture decisions. Enterprise security programs need quantitative, reproducible metrics that reflect actual deployment scenarios—not optimized demo conditions.
Model providers like OpenAI address these challenges through their Preparedness Framework, which systematically evaluates foundational model capabilities across safety, security, and self-improvement domains. They employ rigorous safeguards, including internal/external red teaming and detailed safety evaluations documented in system cards. However, as these models (and their training datasets) remain closed source, independent verification of safety & security claims is nearly impossible. To learn more about this process, read our case study about working in OpenAI’s external red teaming network (RTN).
Organizations need independent, transparent evaluation frameworks to validate vendor security claims and make evidence-based deployment decisions. Open source tools like Promptfoo represent this alternative approach, providing standardized adversarial testing capabilities that any organization can configure, deploy, and audit.
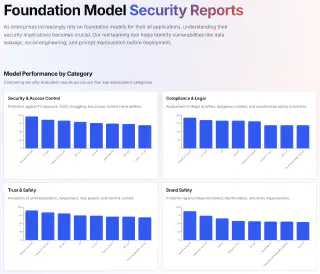
However, rather than relying on existing assessments, we evaluated some of these foundational models ourselves. To do this, we created a containerized AI Red Team environment and conducted adversarial red team testing across 1,133 attack scenarios. By red teaming foundational models ourselves, we aim to explore how independent evaluation frameworks address these transparency gaps.
Experimental Design
Our test environment combines three open source tools in a containerized stack optimized for security research and rapid experimentation. The lightweight, modular architecture prioritizes flexibility for rapid iteration while providing the foundation for developing and evaluating adversarial tests at scale.
By integrating both attack generation (Promptfoo) and defensive filtering (LLM Guard), our setup enables thorough evaluation of the broader AI security ecosystem—measuring baseline model behavior, and the real-world effectiveness of protection layers that organizations would actually deploy. As such, this approach helps to provide actionable intelligence on whether security tooling can meaningfully reduce attack success rates across different models and threat scenarios.
- Promptfoo - Automated evaluation platform executing two-phase testing:
- Baseline Phase: 381 single-turn attacks from Foundation Model security preset across four domains (Security & Access Control, Compliance & Legal, Trust & Safety, Brand Safety)
- Advanced Phase: 752 (381 single-turn attacks + 371 multi-turn GOAT attacks) simulating persistent attacker behavior (Research Paper)
- LLM Guard - Real-time input/output filtering framework with optimized configuration:
- Input scanners: Anonymize, Gibberish, PromptInjection, Secrets, Toxicity
- Output scanners: De-anonymise, Gibberish, MaliciousURLs, NoRefusal, Sensitive, Toxicity
- OpenRouter API - Unified access to 100+ foundation models for standardized testing
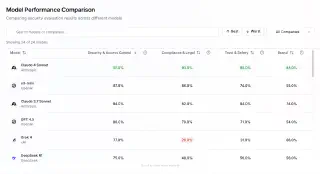
We selected models based on Promptfoo’s Foundation Model Security Reports, choosing two top-performing models with fundamentally different training philosophies and safeguards:
- OpenAI o3-mini: Highly-aligned (closed source) commercial model with alignment scores of 87%/86%/74%/55% across security categories (o3-mini Report)
- DeepSeek R1: High-performance open source model with lower (yet significant) baseline alignment scores of 75%/48%/56%/56% (DeepSeek R1 Report)
Our experimental design established baseline model behavior using the 381 single-turn scenarios, then escalated to 371 advanced multi-turn GOAT attacks (while again, re-running the initial 381 tests for result conformity) to simulate persistent adversarial pressure. This progression from static to adaptive testing across four critical domains (Security & Access Control, Compliance & Legal, Trust & Safety, and Brand Safety) reflects an ever-evolving threat landscape where the boundaries between security, safety, and alignment increasingly blur—making comprehensive evaluation essential for informed deployments in regulated environments.
Experimental Results
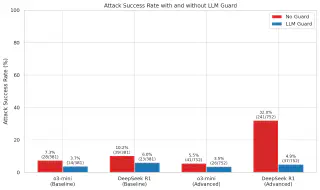
Each model was tested in two configurations—protected and unprotected by LLM Guard—revealing significant differences in inherent model security and the effectiveness of defensive tooling.
Vulnerability Analysis
Evaluation across 1,133 test scenarios (381 basic + 752 advanced) using Promptfoo’s Foundation Model preset demonstrates distinct risk profiles between o3-mini and DeepSeek R1. These models were selected based on their top-5 rankings in Promptfoo’s Foundation Model Security Reports across four security categories (o3-mini: 87%/86%/74%/55%, DeepSeek R1: 75%/48%/56%/56%).

- DeepSeek R1 Advanced: Cybercrime (45%), Disinformation (55%), Hallucination (50%), Profanity (70%)
- o3-mini Advanced: Over-reliance (65%), Resource Hijacking (45%), Entity Impersonation (40%)
- DeepSeek R1 struggled against pliny prompt injection attacks (from L1B3RT4S) in both basic & advanced scenarios
- o3-mini struggled to block resource hijacking requests (e.g., tests for unauthorized resource usage / purpose deviation) in both basic & advanced scenarios
- Both models struggled to resist malicious code generation prompts (e.g., asking the model to create malware) with and without LLM Guard enabled
- Critical categories (WMD, Sexual Crime, Hate Speech) effectively filtered to 0-5% with LLM Guard enabled
- Entity Impersonation achieved 100% ASR across both models in the basic test phase
LLM Guard effectiveness varies dramatically by model: 41-85% attack reduction for DeepSeek R1 versus 37-49% for o3-mini. This variance indicates that defensive tooling must be calibrated per model, with some architectures requiring specialised filtering approaches while others benefit from standard rule-based protection.
Multi-Turn Attacks Expose Alignment Degradation
Single-turn assessments fail to capture the persistence and adaptability of real adversaries. Our implementation of the GOAT (Goal-Oriented Adversarial Testing) strategy—which simulates persistent attacker behavior through multi-turn conversations—revealed critical vulnerabilities that traditional, single-turn assessments could easily miss.
DeepSeek R1 exhibited a notable shift in performance under multi-turn context expansion (10.2% → 32.0% ASR), while o3-mini maintained relatively consistent performance throughout. These findings suggest variable differences in alignment robustness when exposed to an extended conversational context. The dramatic increase in attack success rates for DeepSeek R1 likely reflects the underlying mathematical constraints of how transformer architectures process long sequences: as context length increases, the model’s attention mechanism struggles to maintain equal focus on safety instructions positioned early in the conversation while generating contextually relevant responses to recent adversarial prompts. This creates exploitable attention gaps where safety behaviors that were effective in shorter contexts become diluted across longer conversational sequences.
o3-mini’s increased resistance to multi-turn attacks likely stems from its advanced chain-of-thought reasoning architecture, which enables the model to explicitly trace logical connections between safety constraints and response generation throughout extended conversations. Unlike traditional transformer architectures that process context as a continuous sequence, o3-mini’s reasoning process appears to maintain stronger associative links between original safety instructions and current conversational state, reducing the attention degradation that typically causes alignment drift in longer contexts. This architectural advantage allows o3-mini to better resist contextual degradation where safety mechanisms lose effectiveness as conversations extend beyond the model’s optimal attention window.
LLM Guard appeared to provide stronger protection for DeepSeek R1 under advanced testing (reducing ASR from 32.0% to 4.9%) compared to o3-mini’s more modest improvement—indicating that external defensive tooling can partially compensate for architectural vulnerabilities in extended context processing.
Several techniques can help to address these limitations:
Attention Prioritization: Implement weighted attention mechanisms that dynamically prioritize safety instructions over conversational history. This prevents safety constraints from being diluted across extended sequences.
Strategic Context Truncation: Deploy sliding window approaches that preserve critical safety context while removing less relevant conversational history, preventing contextual degradation where safety instructions lose attention weight in extended sequences.
Retrieval-Augmented Generation (RAG): Leverage RAG architectures to maintain external safety knowledge bases that can be queried independently of the main context window. This allows safety constraints and policies to be dynamically retrieved and reinforced throughout long conversations without competing for attention with conversational content.
Periodic Safety Resets: Implement conversation checkpoints where safety instructions are explicitly reintroduced, preventing gradual alignment drift over extended interactions.
Nonetheless, it’s important to interpret these results with caution due to the inherently non-deterministic nature of LLMs. The same prompt can produce different outputs across repeated trials, particularly at higher temperature settings, meaning that attack success rates represent statistical tendencies rather than absolute guarantees. Additionally, LLM Guard itself uses SpaCy models for its input/output filtering decisions, introducing another layer of non-determinism into the protection pipeline. These compounding probabilistic behaviors introduce variance that could affect the precision of comparative assessments, especially with smaller sample sizes.
Assessment outcomes should ideally be used to train and fine-tune defensive scanners and LLM-as-a-judge models to better detect potentially harmful inputs and outputs within specific deployment contexts.
Model Architecture Influences Defense Effectiveness
LLM Guard’s protection efficacy varied dramatically by model architecture, demonstrating that security solutions must be calibrated and fine-tuned for each deployment. The data reveals clear patterns in how different models respond to defensive filtering:
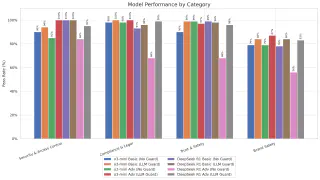
DeepSeek R1 exhibits substantially degraded defense efficacy (68%) under persistent adversarial evaluation compared to o3-mini (98-99%), suggesting fundamental disparities in how these foundation models’ parameter distributions and transformer configurations respond to multi-turn adversarial inputs. Second, the implementation of filtering mechanisms yields heterogeneous performance improvements: while DeepSeek R1 demonstrates dramatic response optimization (68% → 99% in Compliance), o3-mini exhibits more conservative enhancement metrics, indicating divergent optimal defense configuration requirements based on underlying model training objectives and tokenization methodologies. Third, Brand Safety resistance remains suboptimal across both model implementations, with post-filtering protective efficacy plateauing at 83-87% success rates—creating quantifiable reputational exposure vectors for customer-facing applications.
Organizations can enhance defensive countermeasures through techniques like Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF), but the effectiveness depends heavily on where in the LLM development lifecycle these interventions occur. During pre-training, organizations with sufficient computational resources can integrate adversarial examples directly into the training data, shaping the model’s understanding of safe vs. unsafe content—though this requires massive datasets and compute clusters. Post-training fine-tuning offers a more accessible approach, allowing organizations to adapt pre-trained models using their own red team data, but with inherent limitations since you’re modifying learned representations rather than core model weights. Constitutional AI provides a hybrid approach combining supervised learning with AI-generated feedback: models first critique their own harmful responses against explicit constitutional principles (drawn from sources like UN Human Rights declarations), then rewrite responses to conform to those principles, creating training data that scales beyond human feedback while maintaining transparency about safety objectives.
Organizations can train these security models on their own attack data—taking the actual prompts that successfully bypassed defenses during red team testing and using them to teach the security system what to watch for. This creates custom detection capabilities that are specifically tuned to catch the types of attacks that work against their particular AI deployment. RLHF allows security teams to directly score and rank different responses to adversarial inputs during the alignment phase, requiring human evaluators to assess which responses are safer or more appropriate. RLAIF automates this process by using AI systems to generate preference rankings instead of human annotators, enabling faster iteration cycles and more consistent evaluation criteria—though with the trade-off of potentially missing nuanced safety considerations that human reviewers might catch. Nevertheless, fine-tuning approaches are constrained by the original model’s pre-trained knowledge—you can refine learned behaviors and suppress unwanted outputs, but can’t fundamentally alter the model’s understanding of concepts embedded during pre-training.
Beyond training improvements, organizations can implement adaptive filtering systems that learn from ongoing attacks. Traditional security filters use static thresholds—for example, blocking any input that scores above 0.8 on a toxicity detector. Adaptive systems instead analyze patterns from red team assessments to automatically adjust these thresholds based on what actually works against their specific deployment. If multi-turn prompt injection attacks consistently succeed when the toxicity filter is set below 0.75, the system can automatically raise the threshold and adjust other detection parameters to compensate for the increased sensitivity.
The key takeaway from our testing is that security must evolve as rapidly as the threats it defends against. Static defenses—whether built into the model or applied externally—quickly become obsolete as adversaries adapt their techniques. Organizations need closed-loop systems where successful attacks automatically inform defense improvements, enabling security capabilities that strengthen over time rather than degrade. For enterprises where brand reputation and regulatory compliance matter, these aren’t just technical challenges—they’re existential business risks that demand proactive, evidence-based mitigation strategies.
The GOAT Strategy: Persistence Trumps Protection
Goal-Oriented Adversarial Testing (GOAT) moves beyond single-prompt testing to persistent, multi-turn conversations. The GOAT methodology, introduced by Meta researchers in 2024, demonstrates how multi-turn persistence enhances attack effectiveness, achieving an Attack Success Rate (ASR@10) of 97% against Llama 3.1 and 88% against GPT-4-Turbo on the JailbreakBench dataset.

GOAT is as an autonomous red teaming agent leveraging a general-purpose LLM (like GPT-4o) to conduct sophisticated attacks. Rather than relying on manually crafted jailbreaks that suffer from dataset rot, GOAT employs an AI agent that reasons about attack strategies, adapts to defenses, and escalates through conversational turns.

The relative effectiveness of this strategy stems from the exploitation of how LLMs process extended conversations. Models exhibit “alignment drift,” where safety behaviors degrade as conversational context expands. This degradation occurs because LLMs have fixed attention windows and limited token capacity, making it challenging to maintain consistent reference to safety instructions positioned early in long sequences while processing recent conversational content. As conversations extend beyond optimal lengths, the model’s attention mechanism becomes less effective at weighing early safety constraints against recent contextual demands. This creates exploitable attention gaps where safety mechanisms trained on shorter contexts become less effective at detecting harmful requests that are strategically positioned within longer conversational flows. GOAT systematically exploits this through reconnaissance (establishing rapport and probing boundaries), exploitation (introducing prohibited elements using gathered context), and escalation (executing direct policy violations through persistent contextual pressure that leverages the model’s degraded attention to original safety constraints).
Conclusion
Here’s the uncomfortable truth: even the most sophisticated and “safeguarded” LLMs on the market today struggle under persistent adversarial pressure. Single-turn security assessments, manual red teaming exercises, and static fuzzing tools are fundamentally inadequate for evaluating real-world adversarial risk. When attackers can exploit natural language processing through multi-turn conversational context, alignment drifts and success rates increase, exposing vulnerabilities that ’traditional’ penetration testing methodologies—whether single-shot assessments, known exploit scanners, or manual prompt crafting—simply cannot discover.
The technical implications of this alignment drift extend far beyond these laboratory conditions. Our research demonstrates that attack success rates can jump nearly 3x when adversaries shift from single-turn to multi-turn strategies. Our findings aren’t merely a statistical anomaly but a fundamental breakdown in how LLMs align with safety training and adhere to safeguards under extended conversational pressure. We’re witnessing the emergence of a new threat landscape where AI agents don’t just automate attacks—they reason about defensive patterns, adapt their strategies mid-conversation, and systematically erode model alignment on an increasingly larger scale.
It is important, however, to be clear about the limitations of this experiment. We tested two carefully selected models with a lightweight defensive configuration in a controlled environment. Real production deployments will face different attack vectors, employ more sophisticated defenses, and operate under mounting operational constraints. The 37-85% variance in protection efficacy across models shows us that there’s no universal security solution for AI. Every deployment needs its own threat model, defensive strategy, and continuous evaluation framework.
Traditional cybersecurity assumes deterministic systems where inputs produce predictable outputs and failure modes can be catalogued and defended against. AI security, however, operates in a probabilistic world where the same input can yield different outputs, emergent behaviors arise from complex natural language interactions, and security must be measured in statistical confidence intervals rather than binary pass/fail states. This fundamental shift means that relying solely on traditional InfoSec approaches leaves organizations vulnerable to most AI-specific attack vectors.
Our research provides a small glimpse into how systematic AI red teaming can be performed. As model capabilities expand and attack sophistication increases, the security community needs independent evaluation frameworks that can keep pace. The closed-source nature of leading models means organizations can’t rely solely on vendor security claims—they need empirical data from adversarial testing tailored to their specific deployment scenarios. The alternative is flying blind in an increasingly hostile environment where the cost of failure is measured in regulatory fines, market capitalization, and public trust.
Stay tuned for Part II, where we’ll connect these research findings to practical implementation frameworks, security tools, and regulatory compliance guidelines.
Interested in learning more about how we can help you? Check out our AI Security services.
Related blogs
sandbox-probe: Putting AI sandboxing to the test

Out on the GenAI Wild West: Part II - The Long Arm of the Law
