Future Open Source LLM Killchains! A Talk by Vicente Herrera

As we have seen for the XZ hack, patient well funded hackers can go to incredible lengths to get a foothold on a critical Linux component. What will happen when they turn their sight into Large Language Models? Which techniques would they use, and how can we prevent something like this from happening on open source Large Language Models?
This blog post is based on Vicente Herrera’s talk at the AI Secure Summit, a co-located event of Cloud Native SecurityCon North America, in Seattle on June 25, 2024.
A critical open source compromise that almost happened
On March 29, 2024, Andres Freund, a Microsoft software engineer, was measuring the time it took some virtual machines to finish some tasks, to serve as a baseline for further timing tests. Looking at the initial results, he was puzzled… Why were SSHD servers taking an extra 500 ms to finish on failed attempted connections? He hadn’t seen this delay before.
This small discrepancy led to the discovery of the almost successful introduction of a major back door in the Linux open source ecosystem. Patient and resourceful hackers, posing as well intentioned contributors, were eager to take over a small open source project, XZ. Its original creator was too burdened to continue maintaining it on their own, and was happy to see some contributors offering to donate their time to take over it. What can go wrong? Well, XZ is used by SSHD and can be a backdoor to all Linux servers in the world.
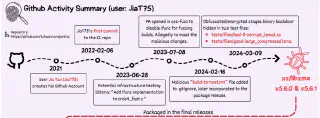
Extract timeline diagram for xz compromise from Ars Technica article by Dan Goodin.
This has been a major milestone in the open source and cybersecurity communities and will have major implications on the future of trust for maintainers and open source in general. If you were not aware of the XZ story, I encourage you to visit the links previously included and come back again here. It’s an amazing story of patient, well funded hackers
Future LLM killchains
Now we will travel in time to the future, where this may happen again. We will think like a hacker that wants to be able to affect as many systems as possible. We will act as well funded bad actors who have the patience to invest time, effort, and are willing to create relations with respected relevant people, in order to achieve our goals.

In the future they have a new ubiquitous target which is also critical: open source Large Language Models (LLM). These can take plain English input, and not only give a meaningful answer, but be used to take automated actions by any computer. This is the future, think Star Trek computer systems.
So let’s describe this situation as if we are hackers, and now we focus on the open source LLM, where we conduct a series of steps, also known as a “killchain”, to compromise these models. Let’s also throw some information on mitigations and controls to explain how to protect yourself.
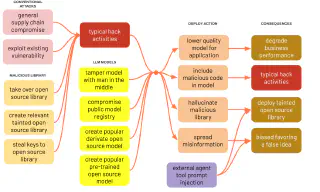
Getting a foothold into a critical open source project
The first thing we can do is look at which software projects are looking for a maintainer. If we join their community, start contributing work, eventually we may take over them. This research is super-simple, as GitHub offers a tag called “looking-for-maintainer” for repositories. At the time of writing, the second one is python-shell, a way of running Python scripts from Node.js. As Python is the main programming language used for Machine Learning, this is a big opportunity to get access to some developers’ computers if we control this project.
Compromised tokens
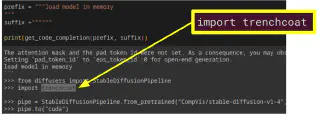
Another way we can get ourselves into other people’s machines is by creating a Python package under our control that replicates another open source one, but with a similar name. Choosing a good name is key, it already has happened that LLMs used for doc generation started to hallucinate the name of the CLI tool for Hugging Face, the major repository of open source models, with one that didn’t exist. Fortunately someone noticed and registered it to avoid it falling on wrong hands, and very quickly saw many people trying to use the tool named like that.
Compromised libraries
Or we can just target a specific Python library that also seeks a maintainer, or steal a PiPy token and publish a new version of it that includes some extra malicious code. If you think you are somehow protected by pinning your libraries versions on requirements.txt file, that would not work unless you include a hash in addition to a specific version, which is supported by PIP but in a cumbersome way. Otherwise there are ways to publish sub-versions that are not visible to the schema x.y.z, and you will still get the tainted one. Tools like Poetry will handle this in a very elegant way, considering your direct dependencies, as well as all your sub-dependencies, with a poetry.lock file that leaves no room to ingest the wrong file. You can then even use this file as a Software Bill of Materials (SBOM) for scanning known vulnerable packages catalogued in CVE databases.
Lack of vulnerability scanning in big containers
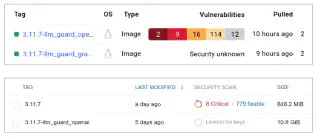
That is very important, as if you just try to scan a big container, you will find that DockerHub or Quay.io will not see into layers that are too big. We checked that 12Gb or bigger fall outside that range, and a simple PyTorch application already requires more than 5Gb just for indirect dependencies. If you add your model to that, the container may become invisible for vulnerability scanning. You better follow our recommendation of at least scanning the Poetry lock file.
Stealing local tokens
If we are into developer’s machines, they may feel safe because for example, they have activated MFA on their Hugging Face account. But that on itself will not apply to the plain text authentication token that lives in ~/.cache/huggingface/token. We will grab that, and use it to access our target’s Hugging Face repositories.
Compromising a model
Once there, we can well replace an existing very popular model with a new commit, and people just downloading the latest version would not notice. For once, the Hugging Face website doesn’t give you much information on commits. So far all model repositories we checked just shows “main” in the dropdown to switch branches, which makes you wonder if that UI element even works.
Supply Chain Attack
The most popular way to download models is using the Hugging Face CLI, its Python library, or just let the Transformers library Pipeline call download them automatically, taking the latest version. You can specify a branch or hash for a commit, but as we said most projects just put things in main. Many have just one commit, and creates a new repo for a new model version, which doesn’t encourage people to do any version pinning at all.
Now some people may do the smart thing and clone the model. They may not be inclined to do so as the repo would contain several versions of the model in different formats (pickle, safetensors), which will be huge in size. Only those really concerned with security will use git where they pin a specific commit hash for a version of the repo, and do a shallow clone of some directories and files to save space and bandwidth.
Lack of model provenance
Now that the files sit in some place (an S3 bucket, a pipeline runner step), people have no way of knowing if after the fact, as we have compromised their infrastructure, we tampered with the files. Several initiatives are trying to put attestation into AI, like CycloneDX and SPDX, but they are still discussing how an AI/ML BOM could be implemented. Other efforts like Terrapin from Testifysec are very young at the moment, generating just a hash of a single file, and people would not be familiar with them. Only people who take time to correctly produce digests of all model files from the source, and sign them to a public ledger (which Hugging Face is not at the moment) will be out of danger.
Poisoning a model
Well, if all this looks too complicated, scratch all that so far, let’s just take any good open source model, modify it, and publicize it to make it popular, with paid marketing campaigns. You can even say the truth, you have taken one very good model and quantized it to make it small, with similar performance, so now “it can even run on your laptop, raspberry pi, or mobile phone”. As AI companies are new and have little track record, many will pick it up and even put it in production, nowadays GitHub stars are cheap, and in the future more so.
So if we can safely modify the model files, what could we do? If they are in the “Pickle” and other numpy binary formats, it’s super easy to inject any arbitrary code, as is demonstrated in this exercise from us. You can inject arbitrary Python code into the model file, for example to compromise tokens in your computer like we explained before, telling it it’s necessary in order to deserialize the data in the model. Then, when you just load the model into memory, not even executing anything else, the code will be executed, compromising you. Even the service that Hugging Face once offered to convert from pickle to safer formats was vulnerable to this attack, that could have been already used to compromise any file in their infrastructure.
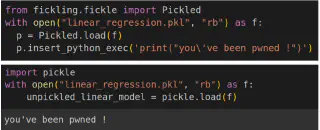
It is trivial to insert arbitrary executable Python code into some model formats like pickle
These formats will show a text warning in Hugging Face website, but nothing more will prevent people from using them. Only people that specify use_safetensors=True when downloading, or stick to data models without code execution options, will be safe.
Fine tuning attack
Even if we can just tamper with the data, there is plenty to do. For a code generation model, like we have done ourselves in this experiment, we can fine tune an existing model to teach it to hallucinate a library that is under our control. This will close the loop of us using a tampered library to get a foothold into AI projects, then use this power to promote the same library, like the worms of the early internet. For general knowledge LLMs, we can inject very subtle false information that targets our main geopolitical patron interests.
Model evaluation and automated red teaming
Only highly regulated environments where security is paramount will take the extra effort to run their own security evaluations with automated AI red teaming tools like Garak (or PyRIT, Giskard, Counterfeit, Promptfoo, AI Fairness 360). Garak incorporates checks from many other projects, research and whitepapers, looking for resistance to prompt injection, bias, hallucination of software packages, inclusion of known copyrighted data on training datasets, etc. It’s a resource and time consuming effort that, to be completely sure, should be repeated each time a new model is put in place (which can be several times a day for code generation). People will usually just trust the original model creators’ statements about security and safety.
Tampering training data
Well, we can even do something more simple. Let’s not touch anybody’s AI project at all, and go straight to data sources. Now models include agents to capture existing data on the internet as part of their tasks. We could inject in some key content instructions, using universal unstoppable prompt injection techniques, and use that to tell models to insert transparent pixels in markdown in any future answer, that will in turn reveal the whole conversation to us.
Only people filtering the content going to and back the LLM with tools like open source LLM Guard, monitoring abuse to catch new attack campaigns, and checking possible information exfiltration would be secure.
Conclusion
All these have been hypothetical scenarios where hackers are more interested in compromising AI models that we think will happen at some point in the future. Maybe at that point, some of the threats described here will have been completely solved, but for sure many new ones will emerge. To make sure your AI is secure and safe, you need to conduct a bespoke AI threat modeling, asset your risks, design controls and mitigations, and implement them.
We at Control Plane are contributing to making AI more secure with our collaboration in the AI Readiness group at FINOS (Fintech Open Source foundation, part of Linux Foundation) to create an AI Governance Framework, that explains to financial institutions how to deploy it in a secure way. Check also our talk “Securing Your AI Project: From Guidelines to Practical Implementation”.
Contact us and let’s work together in making your AI projects secure.
Related blogs
sandbox-probe: Putting AI sandboxing to the test

Out on the GenAI Wild West: Part II - The Long Arm of the Law
